言語を理解するのに
本当に必要な単語数は?
データで読み解く:イディオム頻度と「理解度」の関係
著者: Pavel Ahafonau(パヴェル・アハフォナウ)、R&D責任者
トップ100・500・1000のイディオムを知ると、実際に何が得られるのか?
多くの学習者は「覚えた単語数」で進捗を測りますが、その数字は実際にどれだけ言語を理解できているかをほとんど反映しません。理解度を直接測り、イディオムの知識と結びつけると、学習の進捗ははるかに具体的に可視化できます。下のグラフは、影響力の大きいイディオムの小さなコアから、より広いカバレッジへと進むにつれて、言語理解がどのように変化するかを示しています。
グラフ1. 学習したイディオム数に応じた言語理解の進捗
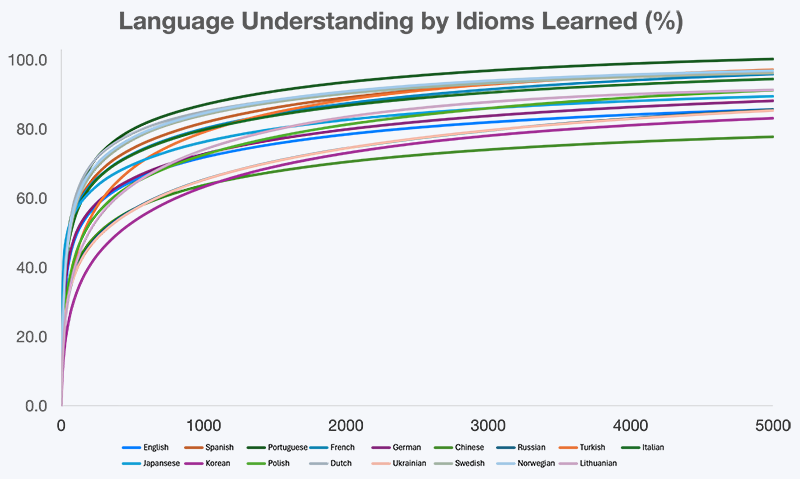
言語理解は一定の速度で増えるわけではありません。グラフが示す通り、最頻出のイディオムを習得すると理解は急速に伸び、その後は「核となる意味の解放」から「ニュアンスの洗練」へと学習が移るにつれて、徐々に伸びが鈍化します。ここで実用的な疑問が生まれます。現実世界で意味のある理解に到達するには、どれくらいのイディオム数で十分なのか。そして、どこから先は追加の努力が逓減していくのか?
この関係は個人レベルでも測定できます。イディオムの習得状況を追跡し、実際の使用頻度と対応づけることで、WRDは学習者の現在の言語理解レベルを継続的に推定し、新しいイディオムを学ぶたびに更新します。
データ、手法、結果を詳しく見ていきましょう:
→ 要旨
→ 1. はじめに
→ 2. データソースと規模
→ 3. イディオム中心の方法論
→ 4. 言語理解の測定
→ 5. 結果
→ 6. なぜイディオムは理解を速く解放するのか
→ 7. 語学学習への示唆
→ 結論
→ 著者について
要旨
語学学習では「言語を理解するには何万語もの単語を暗記する必要がある」という考えが一般的です。本研究はこの前提に疑問を投げかけ、語彙数そのものではなく、高頻度イディオムの習得数に応じて言語理解がどのように伸びるかを分析します。実世界の言語使用から得られた大規模言語データを用い、トップ100・500・1000のイディオムを習得することで学習者が実際に何を得るのかを定量化し、孤立した単語ではなくイディオムこそが「本当の理解」を駆動する主要因であることを示します。
1. はじめに
言語は、孤立した単語の集合として使われているわけではありません。日常会話、書籍、映画、記事、百科事典的テキストでは、意味は定型表現、文法構文、イディオム的パターンを通じて伝達されます。従来の語彙中心の学習アプローチは、言語が実際にどう使われているかを見落としがちなため、現実の理解につながらないことが少なくありません。
本研究は、次の根本的な問いに取り組みます。
最重要のイディオムを習得することで、学習者は現実的に言語のどれくらいを理解できるのか?
2. データソースと規模
本研究は、実世界の言語使用に関する大規模分析に基づいています。会話言語、映画と字幕、書籍、記事、百科事典・教育テキストに加え、公開されているコーパス資源や、言語間でイディオムと単語を結びつける語彙データなどのオープンデータセットも集約して利用しました。総計として、分析は数十億語規模の多言語コーパスを対象とし、ウェブおよび出版物から収集されたデータを通じて、人々が日常のコミュニケーションで接し、使用する言語の相当部分をカバーしています。
3. イディオム中心の方法論
3.1 単語からイディオムへ
本研究では、表層的な語形を数えるのではなく、イディオムを意味の主要単位として扱います。ここでのイディオムには、定型表現だけでなく、複数の語形変化を代表する文法的な基本形も含まれます。
高度な言語モデル群を用いて、私たちは次を行いました。
- すべての文法的語形を基本イディオムへ統合(例:“am,” “is,” “are,” “was” → “be”)
- 語形を別イディオムとして扱うのは、その言語内で異なるイディオム的意味を持つ場合に限る
この正規化により、次が可能になりました。
- 正確な頻度測定
- 言語間での比較可能性
- 人工的な語彙数の水増しの排除
その結果、実際の使用頻度と中核となる意味単位の間に、精密な対応関係を構築できました。
4. 言語理解の測定
言語理解は、外部の助けなしに学習者が理解できる実世界コンテンツの割合として定義しました。これには次の能力が含まれます。
- 会話を追える
- 文章を理解できる
- 頻繁に調べ物をせずにメディアを楽しめる
- 含意、構造、文脈を把握できる
理解度は、次を習得した時点で測定しました。
- トップ100イディオム
- トップ500イディオム
- トップ1000イディオム
- 高度分析のための3000〜5000イディオムの拡張レンジ
本研究を踏まえ、WRDは同じ測定原理を個々の学習者にも適用しています。ユーザーが新しいイディオムを学ぶたびに理解度を段階的に再計算し、語彙数から間接的に推測するのではなく、高精度に理解を追跡できるようにします。このアプローチは、データで観測された実世界の使用パターンを反映し、継続的で粒度の細かい進捗測定を可能にします。
5. 結果
5.1. イディオム語彙サイズ別の言語理解
17言語にわたる研究結果の要約を、以下の表に示します。イディオム知識が増えるにつれて、実世界の言語理解がどの程度になるかを推定しています。
表1. 学習したトップイディオムに基づく言語理解(%)の要約
| 言語 | イディオム語彙の閾値別の理解度(%) | ||||
|---|---|---|---|---|---|
| トップ100 | トップ500 | トップ1000 | トップ3000 | トップ5000 | |
| 英語 | 48.8 | 64.9 | 71.8 | 81.9 | 85.6 |
| スペイン語 | 49.6 | 66.3 | 73.5 | 84.1 | 87.5 |
| ポルトガル語 | 58.8 | 78.2 | 85.0 | 94.3 | 97.2 |
| フランス語 | 52.7 | 68.1 | 75.2 | 86.0 | 89.6 |
| ドイツ語 | 47.8 | 63.3 | 70.1 | 80.5 | 84.0 |
| 中国語 | 40.3 | 56.7 | 63.7 | 74.0 | 77.8 |
| ロシア語 | 38.7 | 56.5 | 65.0 | 79.1 | 85.0 |
| トルコ語 | 42.9 | 68.6 | 79.1 | 92.9 | 97.1 |
| イタリア語 | 47.6 | 64.3 | 71.2 | 81.5 | 84.7 |
| 日本語 | 56.5 | 69.7 | 76.3 | 86.0 | 89.5 |
| 韓国語 | 31.9 | 53.0 | 63.2 | 78.0 | 83.1 |
| ポーランド語 | 43.1 | 62.8 | 71.1 | 84.1 | 88.4 |
| オランダ語 | 57.3 | 74.7 | 80.7 | 88.6 | 91.0 |
| ウクライナ語 | 36.9 | 54.4 | 63.2 | 77.4 | 83.0 |
| スウェーデン語 | 52.9 | 71.4 | 78.1 | 86.5 | 88.9 |
| ノルウェー語 | 52.8 | 70.7 | 77.4 | 86.2 | 88.6 |
| リトアニア語 | 38.2 | 60.5 | 70.3 | 83.5 | 86.6 |
正確な割合は言語によって異なるものの、全体のパターンは一貫しています。比較的少数の高頻度イディオムが、実世界の理解の大部分を占めているのです。これらの結果を実用的にするため、次のセクションでは、本研究で分析した各言語について、最頻出の単語・イディオムの言語別リスト(まずはトップ100)を提示します。
言語別:学ぶべきトップイディオム・リスト
→ 英語 → スペイン語 → ポルトガル語 → フランス語 → ドイツ語 → 中国語 → ロシア語 → トルコ語 → イタリア語 → 日本語 → 韓国語 → ポーランド語 → オランダ語 → ウクライナ語 → スウェーデン語 → ノルウェー語 → リトアニア語
5.2. 結果の解釈
いくつかの一貫したパターンが見られます。
- 序盤の伸びが大きい:最初の500イディオムで日常言語の大部分が解放され、理解度はしばしば55〜75%に到達します。
- 1000イディオムで実用的な理解:1000イディオム前後で、会話を無理なく追い、簡易化されたネイティブ文章を読み、最小限の補助でメディアを楽しめるようになります。
- 3000イディオムで高度な理解:3000イディオム帯は高い実用流暢性に対応し、理解度が80〜90%を超えることも多いです。
- 5000イディオム以降は逓減:追加のイディオムは、新しいコンテンツの解放というより、主に文体的ニュアンスを増やします。
5.3. 言語間の一貫性
文法、文字体系、文化的構造の違いにもかかわらず、理解曲線の形は17言語すべてで驚くほど似ています。これは言語使用の普遍的性質を示唆します。すなわち、意味は比較的少数の高頻度イディオム的パターンに集中しているのです。
6. なぜイディオムは理解を速く解放するのか
イディオムは意味の圧縮単位として機能します。各イディオムは次を内包します。
- 複数の単語
- 文法構造
- 文化的・文脈的な意味
イディオムを認識できると、脳は単語ごとに意味を組み立て直すのではなく、意味を即座に処理できます。これにより認知負荷が下がり、読解・リスニングの双方で理解が加速します。
7. 語学学習への示唆
本研究の知見は、学習者・教育者・語学学習プロダクト設計に直接的な示唆を与えます。
- 早い段階から高頻度イディオムを優先する
- 進捗は語彙数ではなく理解度(%)で測る
- 理論的な網羅性ではなく実際の使用に最適化する
イディオムは上級者向けの素材ではなく、現実の理解の土台です。
結論
言語を理解するのに、何万語もの単語を知る必要はありません。必要なのは、その言語が実際にどう使われているかを知ることです。
最重要のイディオムに集中することで、学習者は早い段階で不釣り合いなほど大きな意味の割合を解放し、より速い理解、より高い自信、そして本物のコンテンツへの早期アクセスを得られます。言語理解は「積み上げ」ではなく、「優先順位づけ」によって伸びるのです。
著者について
Pavel AhafonauはWRDのR&D責任者。AIによる学習最適化、大規模言語モデリング、そして人間の学習効率を最大化するパーソナライズド・システムの設計に取り組んでいます。