要真正聽懂一門語言,
你到底需要
多少單字?
以資料為基礎的分析:語言理解與習語頻率
作者:Pavel Ahafonau,R&D 負責人
實際上,掌握前 100、500、1000 個習語究竟能帶來什麼?
許多學習者會用「背了多少單字」來追蹤進度,但這個數字往往無法反映 你到底能聽懂多少真實語言。當我們直接測量理解力,並把它與習語掌握程度連結起來,學習進展就會變得更具體、更可視化。下方圖表展示了:當學習者從少量高影響力的核心習語,逐步走向更廣泛的覆蓋時,語言理解會如何演變。
圖 1. 語言理解進展與已學習習語數量的關係
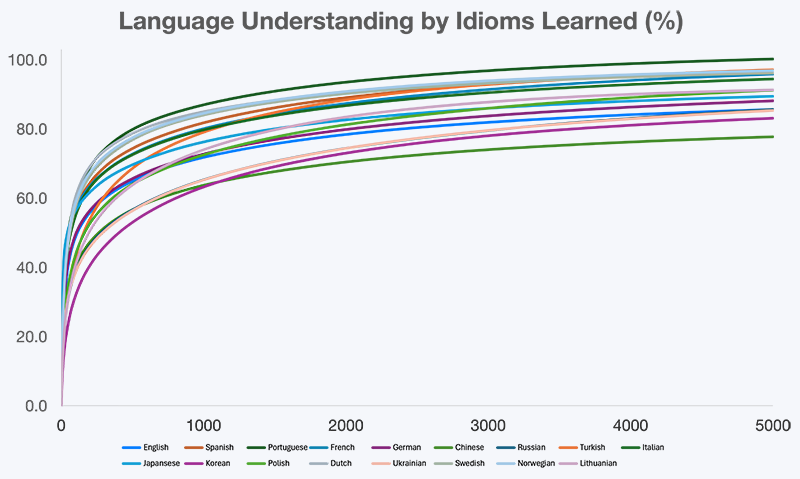
語言理解並不是以固定速度成長。正如圖表所示,當學習者掌握最常用的高頻習語時,理解力會快速提升;之後則會逐步放緩,因為學習重心從「解鎖核心意義」轉向「打磨細微差異」。這引出一個實用問題:到底需要多少習語才算足夠,才能達到有意義的真實世界理解 —— 又從哪裡開始,額外投入會出現報酬遞減?
這種關係也可以在個體層級進行測量。透過追蹤習語習得情況,並將其映射到真實使用頻率,WRD 能夠持續估算學習者當前的語言理解程度,並在每學會一個新習語後即時更新。
深入探索資料、方法與研究發現:
→ 摘要
→ 1. 引言
→ 2. 資料來源與規模
→ 3. 以習語為中心的方法論
→ 4. 語言理解的衡量方式
→ 5. 結果
→ 6. 為什麼習語能更快解鎖理解力
→ 7. 對語言學習的啟示
→ 結論
→ 關於作者
摘要
語言學習中常見的一種觀念是:要聽懂一門語言,必須背下數以萬計的單字。本研究透過分析 語言理解如何隨著高頻習語的學習數量而擴展(而非單純的詞彙量),對此提出挑戰。我們使用源自真實語言使用情境的大規模語言資料,量化學習者掌握前 100、500、1000 個習語後究竟能獲得什麼 —— 並證明為什麼真正驅動理解的,是習語(而非孤立的單字)。
1. 引言
語言並不是以一堆孤立單字的形式被使用。在日常對話、書籍、電影、文章與百科文本中,意義是透過 固定表達、語法結構與慣用模式 來傳遞的。傳統以詞彙為核心的學習方式,往往難以轉化為真實理解,因為它忽略了語言在現實中的使用方式。
本研究聚焦於一個根本問題:
如果掌握一門語言中最重要的習語,學習者實際上能聽懂多少?
2. 資料來源與規模
本研究基於對 真實世界語言使用 的大規模分析,資料涵蓋口語對話、電影與字幕、書籍、文章、百科與教育文本,以及來自公開可用的 語料庫(corpus) 資源與跨語言連結習語與單字的詞彙庫之彙整開放資料集。整體而言,本分析涵蓋了 由數十億詞彙構成的大規模多語種語料,來源包括網路與出版物,代表人們在日常溝通中所接觸與使用語言的相當大一部分。
3. 以習語為中心的方法論
3.1 從單字到習語
本研究不以表層詞形的數量作為衡量,而是將 習語視為意義的主要單位。此處的「習語」不僅包含固定表達,也包含可代表多種詞形變化的語法基底形式。
我們使用一組先進語言模型,進行以下處理:
- 將所有語法詞形合併到其基底習語(例如 “am,” “is,” “are,” “was” → “be”)
- 僅在詞形於該語言中承載 不同的慣用語義 時,才將其視為獨立習語
這種正規化使我們能夠:
- 精準測量頻率
- 在不同語言間進行可比對分析
- 消除人為的詞彙膨脹
最終,我們建立了 真實使用頻率 與 核心語義單位 之間的精確映射。
4. 語言理解的衡量方式
本研究將語言理解定義為:學習者在不借助外部協助的情況下,能理解的真實世界內容比例。這包括以下能力:
- 跟上口語對話
- 理解書面文本
- 在不頻繁查找的情況下消費媒體內容
- 掌握隱含意義、結構與語境
理解程度在掌握以下習語數量後進行測量:
- 前 100 個習語
- 前 500 個習語
- 前 1000 個習語
- 用於進階分析的延伸範圍:3000–5000 個習語
基於本研究,WRD 也在個體學習者層級採用相同的衡量原則。當使用者學會新的習語時,系統會以增量方式重新計算語言理解程度,使理解力能以高精度被追蹤,而不是從詞彙量間接推測。此方法反映了資料中觀察到的真實使用模式,並支援持續、細緻的進度量測。
5. 結果
5.1. 語言理解與習語詞彙量的關係
本研究針對 17 種語言 的彙總結果如下(見 下表),展示了隨著習語掌握程度提升,真實世界語言理解的估計值。
表 1. 基於已掌握高頻習語的語言理解(%)彙總
| 語言 | 不同習語詞彙門檻下的理解(%) | ||||
|---|---|---|---|---|---|
| 前 100 | 前 500 | 前 1000 | 前 3000 | 前 5000 | |
| 英語 | 48.8 | 64.9 | 71.8 | 81.9 | 85.6 |
| 西班牙語 | 49.6 | 66.3 | 73.5 | 84.1 | 87.5 |
| 葡萄牙語 | 58.8 | 78.2 | 85.0 | 94.3 | 97.2 |
| 法語 | 52.7 | 68.1 | 75.2 | 86.0 | 89.6 |
| 德語 | 47.8 | 63.3 | 70.1 | 80.5 | 84.0 |
| 中文 | 40.3 | 56.7 | 63.7 | 74.0 | 77.8 |
| 俄語 | 38.7 | 56.5 | 65.0 | 79.1 | 85.0 |
| 土耳其語 | 42.9 | 68.6 | 79.1 | 92.9 | 97.1 |
| 義大利語 | 47.6 | 64.3 | 71.2 | 81.5 | 84.7 |
| 日語 | 56.5 | 69.7 | 76.3 | 86.0 | 89.5 |
| 韓語 | 31.9 | 53.0 | 63.2 | 78.0 | 83.1 |
| 波蘭語 | 43.1 | 62.8 | 71.1 | 84.1 | 88.4 |
| 荷蘭語 | 57.3 | 74.7 | 80.7 | 88.6 | 91.0 |
| 烏克蘭語 | 36.9 | 54.4 | 63.2 | 77.4 | 83.0 |
| 瑞典語 | 52.9 | 71.4 | 78.1 | 86.5 | 88.9 |
| 挪威語 | 52.8 | 70.7 | 77.4 | 86.2 | 88.6 |
| 立陶宛語 | 38.2 | 60.5 | 70.3 | 83.5 | 86.6 |
雖然各語言的具體百分比有所差異,但整體模式一致:相對少量的高頻習語,就能覆蓋真實世界理解的很大一部分。為了讓這些結果更具實用性,接下來的章節提供了各語言最常見單字與習語的清單,從本研究所分析的每種語言的前 100 個開始。
各語言建議學習的高頻習語清單
→ 英語 → 西班牙語 → 葡萄牙語 → 法語 → 德語 → 中文 → 俄語 → 土耳其語 → 義大利語 → 日語 → 韓語 → 波蘭語 → 荷蘭語 → 烏克蘭語 → 瑞典語 → 挪威語 → 立陶宛語
5.2. 結果解讀
我們觀察到幾個一致的模式:
- 前期增長強勁:前 500 個習語 就能解鎖大量日常語言內容,理解度常可達到 55–75%。
- 1000 個習語達到功能性理解:約在 1000 個習語 左右,學習者通常能較輕鬆地跟上對話、閱讀簡化的母語文本,並在最少支援下消費媒體內容。
- 3000 個習語達到進階理解:3000 個習語 的範圍對應到高功能性的流利度,理解度往往超過 80–90%。
- 超過 5000 個習語後報酬遞減:新增習語主要帶來風格與語感的細微差異,而非解鎖全新內容。
5.3. 跨語言一致性
儘管語法、書寫系統與文化結構各不相同,在所有 17 種語言中,理解曲線的形狀都驚人地相似。這顯示語言使用具有一種普遍特性:意義集中在相對少量的高頻慣用模式之中。
6. 為什麼習語能更快解鎖理解力
習語可視為 語義壓縮單元。每個習語都封裝了:
- 多個單字
- 語法結構
- 文化與語境意義
一旦識別出習語,大腦就能即時處理其意義,而不必逐字重建,從而降低認知負荷,並加速閱讀與聽力理解。
7. 對語言學習的啟示
這些發現對學習者、教育者與語言學習產品設計具有直接意義:
- 早期優先學習 高頻習語
- 用 理解百分比(%) 衡量進度,而不是詞彙量
- 以 真實使用 為導向優化學習,而非追求理論上的「完整」
習語不是進階內容 —— 它是通往真實理解的基礎。
結論
要聽懂一門語言,你不需要背下數以萬計的單字。你需要知道 語言在現實中是如何被使用的。
透過聚焦最重要的習語,學習者能在早期就解鎖不成比例的大量意義,更快達到理解、更有信心,並更早接觸到真實內容。語言理解的成長,不在於堆疊,而在於取捨與優先順序。
關於作者
Pavel Ahafonau 是 WRD 的 R&D 負責人。他的研究聚焦於 AI 驅動的學習最佳化、大規模語言建模,以及旨在最大化人類學習效率的個人化系統。