要真正听懂一门语言,
你到底需要
多少词?
基于数据的分析:语言理解与习语频率
作者:Pavel Ahafonau,R&D 负责人
掌握前 100、500、1000 个习语,实际能带来什么?
很多学习者用“学了多少单词”来衡量进度,但这个数字往往并不能反映 你到底能听懂多少真实语言。当我们直接测量理解力,并将其与习语掌握程度关联起来,学习进展就会变得更直观、更具体。下图展示了:当学习者从少量高影响力的核心习语,逐步扩展到更广覆盖时,语言理解如何演变。
图 1. 随已掌握习语数量变化的语言理解进度
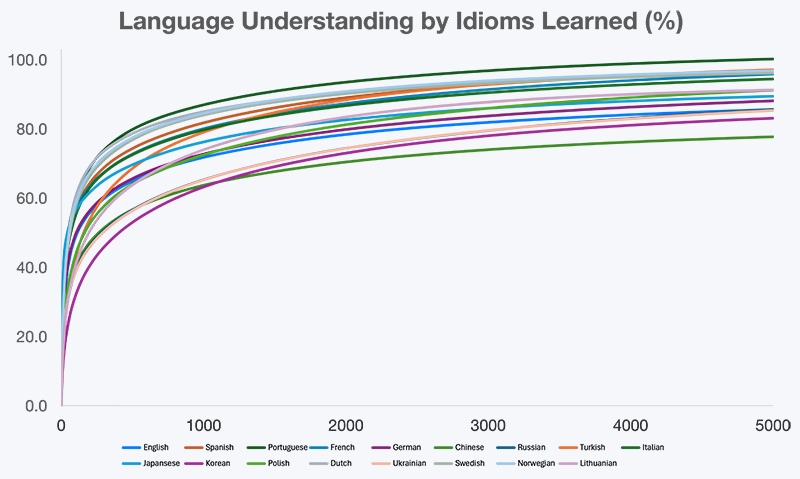
语言理解并不是以恒定速度增长的。正如图中所示,当学习者掌握最常用的习语时,理解力会快速提升;随后增长逐渐放缓,因为学习的重心从“打开核心含义”转向“打磨细微差别”。这引出了一个非常实际的问题:到底需要多少习语,才能达到有意义的真实世界理解——以及从哪里开始,额外投入会出现明显的边际递减?
这种关系也可以在个体层面进行测量。通过追踪习语习得,并将其映射到真实使用频率,WRD 会持续估算学习者当前的语言理解水平,并在每学会一个新习语后更新该估算。
深入了解数据、方法与结论:
→ 摘要
→ 1. 引言
→ 2. 数据来源与规模
→ 3. 以习语为中心的方法论
→ 4. 语言理解的测量
→ 5. 结果
→ 6. 为什么习语能更快打开理解
→ 7. 对语言学习的启示
→ 结论
→ 关于作者
摘要
语言学习中有一种常见观点:要理解一门语言,必须背下数以万计的单词。本研究通过分析 语言理解如何随高频习语的学习数量而扩展(而非单纯的词汇量)来挑战这一假设。我们基于来自真实语言使用的大规模语言学数据,定量评估学习者掌握前 100、500、1000 个习语后究竟能获得什么,并说明为什么推动真实理解的关键是习语,而不是孤立的单词。
1. 引言
语言并不是以孤立单词的集合来使用的。在日常对话、书籍、电影、文章以及百科类文本中,意义通过 稳定表达、语法结构与习语化模式 来传递。传统的“背词汇”学习方式之所以常常无法转化为真实理解,是因为它忽略了语言在现实中的使用方式。
本研究聚焦一个根本问题:
如果掌握一门语言中最重要的习语,学习者现实中能理解这门语言的多少?
2. 数据来源与规模
本研究基于对 真实语言使用 的大规模分析,数据来源包括口语对话、电影与字幕、书籍、文章、百科与教育类文本,以及来自公开可用的 语料库 资源与跨语言连接习语与词汇的词表等聚合开放数据集。总体而言,本分析覆盖了 由数十亿词构成的大规模多语种语料,来源于网络与出版材料,代表了人们在日常交流中接触并使用的语言的相当大一部分。
3. 以习语为中心的方法论
3.1 从单词到习语
本研究不再统计表层词形,而是将 习语视为意义的基本单位。这里的“习语”不仅包括固定表达,也包括能够代表多个词形变体的语法基本形式。
借助一组先进的语言模型,我们:
- 将所有语法词形合并到其基本习语中(例如 “am”、“is”、“are”、“was” → “be”)
- 仅在词形在该语言中承载 不同的习语化含义 时,才将其视为独立习语
这种归一化使我们能够:
- 准确测量频率
- 实现跨语言可比性
- 消除人为“膨胀”的词汇量
最终得到的是 真实使用频率 与 核心语义单位 之间的精确映射。
4. 语言理解的测量
我们将语言理解定义为:学习者在无需外部帮助的情况下,能够理解的 真实世界内容的百分比。这包括以下能力:
- 跟上口语对话
- 理解书面文本
- 在不频繁查找的情况下消费媒体内容
- 把握隐含意义、结构与语境
理解水平在掌握以下范围后进行测量:
- 前 100 个习语
- 前 500 个习语
- 前 1000 个习语
- 用于进阶分析的扩展范围:3000–5000 个习语
基于这项研究,WRD 将同样的测量原则应用到个体学习者层面。随着用户学习新的习语,系统会以增量方式重新计算语言理解水平,从而以高精度追踪理解力,而不是从词汇量间接推断。这一方法反映了数据中观察到的真实使用模式,并支持对进度进行持续、细粒度的测量。
5. 结果
5.1. 习语词汇量与语言理解
本研究覆盖 17 种语言 的汇总结果见 下表,展示了随着习语掌握量增加,真实世界语言理解的估计值。
表 1. 基于已掌握高频习语的语言理解(%)汇总
| 语言 | 不同习语词汇阈值下的理解(%) | ||||
|---|---|---|---|---|---|
| 前 100 | 前 500 | 前 1000 | 前 3000 | 前 5000 | |
| 英语 | 48.8 | 64.9 | 71.8 | 81.9 | 85.6 |
| 西班牙语 | 49.6 | 66.3 | 73.5 | 84.1 | 87.5 |
| 葡萄牙语 | 58.8 | 78.2 | 85.0 | 94.3 | 97.2 |
| 法语 | 52.7 | 68.1 | 75.2 | 86.0 | 89.6 |
| 德语 | 47.8 | 63.3 | 70.1 | 80.5 | 84.0 |
| 中文 | 40.3 | 56.7 | 63.7 | 74.0 | 77.8 |
| 俄语 | 38.7 | 56.5 | 65.0 | 79.1 | 85.0 |
| 土耳其语 | 42.9 | 68.6 | 79.1 | 92.9 | 97.1 |
| 意大利语 | 47.6 | 64.3 | 71.2 | 81.5 | 84.7 |
| 日语 | 56.5 | 69.7 | 76.3 | 86.0 | 89.5 |
| 韩语 | 31.9 | 53.0 | 63.2 | 78.0 | 83.1 |
| 波兰语 | 43.1 | 62.8 | 71.1 | 84.1 | 88.4 |
| 荷兰语 | 57.3 | 74.7 | 80.7 | 88.6 | 91.0 |
| 乌克兰语 | 36.9 | 54.4 | 63.2 | 77.4 | 83.0 |
| 瑞典语 | 52.9 | 71.4 | 78.1 | 86.5 | 88.9 |
| 挪威语 | 52.8 | 70.7 | 77.4 | 86.2 | 88.6 |
| 立陶宛语 | 38.2 | 60.5 | 70.3 | 83.5 | 86.6 |
尽管不同语言的具体百分比有所差异,但总体规律一致:相对较小的一组高频习语,就能覆盖真实世界理解的很大一部分。为了让这些结果更具可操作性,接下来的部分提供了本研究所分析的每种语言的高频词与习语清单,从各语言的前 100 开始。
按语言学习的高频习语清单
→ 英语 → 西班牙语 → 葡萄牙语 → 法语 → 德语 → 中文 → 俄语 → 土耳其语 → 意大利语 → 日语 → 韩语 → 波兰语 → 荷兰语 → 乌克兰语 → 瑞典语 → 挪威语 → 立陶宛语
5.2. 结果解读
我们观察到若干一致的规律:
- 前期收益显著:最初的 500 个习语 就能解锁大量日常语言内容,理解度常常达到 55–75%。
- 1000 个习语达到可用理解:在约 1000 个习语 的水平,学习者通常可以较为轻松地跟上对话、阅读简化的母语文本,并在少量辅助下消费媒体内容。
- 3000 个习语达到进阶理解:3000 个习语 左右对应较高的功能性流利度,理解度往往超过 80–90%。
- 超过 5000 个习语边际递减:新增习语主要带来风格与细微差别,而不是解锁全新内容。
5.3. 跨语言一致性
尽管语法、书写系统与文化结构各不相同,这 17 种语言的理解曲线形状却惊人地相似。这表明语言使用具有一种普遍属性:意义集中在相对较小的一组高频习语化模式中。
6. 为什么习语能更快打开理解
习语可以视为 语义压缩单元。每个习语都封装了:
- 多个单词
- 语法结构
- 文化与语境含义
识别一个习语,能让大脑即时处理整体含义,而不是逐词重建,从而降低认知负荷,并加速阅读与听力理解。
7. 对语言学习的启示
这些发现对学习者、教育者以及语言学习产品设计都有直接影响:
- 尽早优先学习 高频习语
- 用 理解度(%) 衡量进度,而不是词汇量
- 围绕 真实使用 优化学习,而非追求理论上的“完整”
习语并不是进阶材料——它们是实现真实理解的基础。
结论
要听懂一门语言,你不需要掌握数以万计的单词。你需要知道 这门语言在现实中是如何被使用的。
当学习者把重点放在最重要的习语上,就能在早期解锁不成比例的大量意义,更快获得理解、更强的信心,并更早接触真实内容。语言理解的增长,不在于堆积,而在于优先级。
关于作者
Pavel Ahafonau 是 WRD 的 R&D 负责人。他的工作聚焦于 AI 驱动的学习优化、大规模语言建模,以及旨在最大化人类学习效率的个性化系统。