Hoeveel woorden
heb je echt nodig om
een taal te begrijpen?
Een datagedreven analyse van taalbegrip op basis van idiomfrequentie
Auteur: Pavel Ahafonau, Head of R&D
Wat levert het je in de praktijk op als je de top 100, 500 en 1000 idiomen kent?
Veel leerlingen volgen hun vooruitgang door het aantal geleerde woorden te tellen, maar dat getal weerspiegelt zelden hoeveel echte taal ze daadwerkelijk kunnen begrijpen. Wanneer begrip direct wordt gemeten en gekoppeld aan idiomkennis, wordt leerprogressie veel concreter zichtbaar. De grafiek hieronder laat zien hoe taalbegrip zich ontwikkelt wanneer leerlingen van een kleine kern van idiomen met grote impact naar bredere dekking gaan.
Grafiek 1. Vooruitgang in taalbegrip op basis van het aantal geleerde idiomen
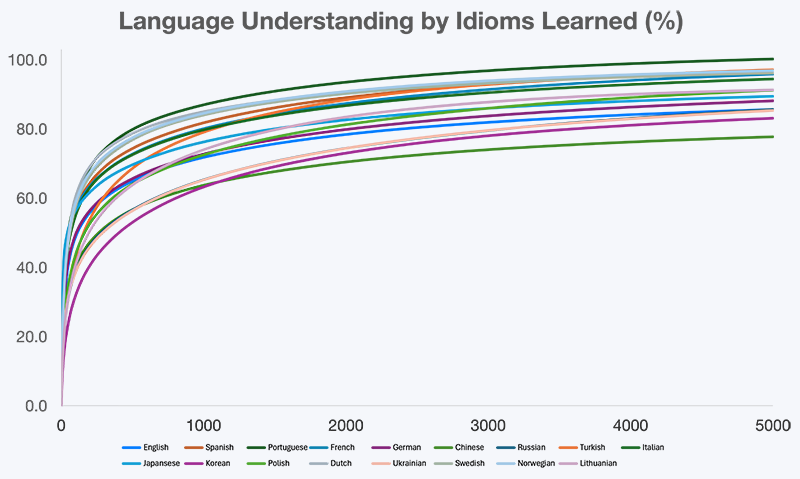
Taalbegrip neemt niet met een constante snelheid toe. Zoals de grafiek laat zien, groeit begrip snel wanneer leerlingen de meest gebruikte idiomen verwerven, en vertraagt het daarna geleidelijk wanneer leren verschuift van het ontsluiten van kernbetekenis naar het verfijnen van nuance. Dit patroon roept een praktische vraag op: hoeveel idiomen zijn genoeg om betekenisvol begrip in de echte wereld te bereiken — en vanaf welk punt levert extra inspanning steeds minder op?
Deze relatie kan ook op individueel niveau worden gemeten. Door idiomverwerving te volgen en die te koppelen aan gebruiksfrequentie in de praktijk, schat WRD continu het huidige niveau van taalbegrip van een leerling en werkt dit bij met elk nieuw geleerd idioom.
Duik erin en ontdek de data, methodologie en bevindingen:
→ Samenvatting
→ 1. Inleiding
→ 2. Databronnen en schaal
→ 3. Idiomgerichte methodologie
→ 4. Taalbegrip meten
→ 5. Resultaten
→ 6. Waarom idiomen begrip sneller ontsluiten
→ 7. Implicaties voor taalleren
→ Conclusie
→ Over de auteur
Samenvatting
Een veelvoorkomende overtuiging bij taalleren is dat je een taal pas kunt begrijpen als je tienduizenden woorden uit je hoofd leert. Deze studie zet die aanname op losse schroeven door te analyseren hoe taalbegrip meegroeit met het aantal geleerde hoogfrequente idiomen, in plaats van met de ruwe grootte van de woordenschat. Met grootschalige taalkundige data uit echt taalgebruik kwantificeren we wat leerlingen daadwerkelijk winnen door de top 100, 500 en 1000 idiomen te beheersen — en laten we zien waarom idiomen, en niet losse woorden, de belangrijkste drijvers zijn van echt begrip.
1. Inleiding
Taal wordt niet gebruikt als een verzameling losse woorden. In dagelijkse gesprekken, boeken, films, artikelen en encyclopedische teksten wordt betekenis overgebracht via vaste uitdrukkingen, grammaticale constructies en idiomatische patronen. Traditionele benaderingen die vooral op woordenschat zijn gebaseerd, vertalen zich vaak niet naar echt begrip, omdat ze negeren hoe taal in de praktijk wordt gebruikt.
Dit onderzoek behandelt een fundamentele vraag:
Hoeveel van een taal kan een leerling realistisch begrijpen door de belangrijkste idiomen te beheersen?
2. Databronnen en schaal
De studie is gebaseerd op een uitgebreide grootschalige analyse van echt taalgebruik, met data uit conversatietaal, films en ondertitels, boeken, artikelen, encyclopedische en educatieve teksten, evenals geaggregeerde open datasets uit publiek beschikbare corpus-bronnen en woordenlijsten die idiomen en woorden tussen talen koppelen. In totaal omvatte de analyse grootschalige meertalige corpora met miljarden woorden, afkomstig van het web en gepubliceerde materialen, die een aanzienlijk deel vertegenwoordigen van de taal waarmee mensen in dagelijkse communicatie in aanraking komen en die ze gebruiken.
3. Idiomgerichte methodologie
3.1 Van woorden naar idiomen
In plaats van oppervlakkige woordvormen te tellen, beschouwt deze studie idiomen als de primaire eenheid van betekenis. Een idioom omvat hier niet alleen vaste uitdrukkingen, maar ook grammaticale basisvormen die meerdere woordvarianten vertegenwoordigen.
Met behulp van een set geavanceerde taalmodellen hebben we:
- Alle grammaticale woordvormen samengevoegd tot hun basisidioom (bijv. “am,” “is,” “are,” “was” → “be”)
- Woordvormen alleen als aparte idiomen behandeld wanneer ze onderscheidende idiomatische betekenissen binnen een taal droegen
Deze normalisatie maakte het mogelijk om:
- Frequentie nauwkeurig te meten
- Talen onderling te vergelijken
- Kunstmatige inflatie van woordenschat te elimineren
Het resultaat was een precieze koppeling tussen werkelijke gebruiksfrequentie en kern-semantische eenheden.
4. Taalbegrip meten
Taalbegrip werd gedefinieerd als het percentage van echte content dat een leerling kan begrijpen zonder externe hulp. Dit omvat het vermogen om:
- Gesproken gesprekken te volgen
- Geschreven teksten te begrijpen
- Media te consumeren zonder voortdurend op te zoeken
- Impliciete betekenis, structuur en context te vatten
Begripsniveaus werden gemeten na het leren van:
- Top 100 idiomen
- Top 500 idiomen
- Top 1000 idiomen
- Uitgebreide bereiken van 3000–5000 idiomen voor geavanceerde analyse
Voortbouwend op dit onderzoek past WRD dezelfde meetprincipes toe op het niveau van de individuele leerling. Naarmate gebruikers nieuwe idiomen leren, wordt taalbegrip stapsgewijs herberekend, waardoor begrip met hoge precisie kan worden gevolgd in plaats van indirect te worden afgeleid uit de grootte van de woordenschat. Deze aanpak weerspiegelt de gebruikspatronen uit de praktijk die in de data zijn waargenomen en maakt continue, fijnmazige meting van vooruitgang mogelijk.
5. Resultaten
5.1. Taalbegrip op basis van de grootte van de idiomwoordenschat
De samengevatte resultaten van de studie over 17 talen worden weergegeven in de tabel hieronder, met een schatting van het begrip van taal in de praktijk naarmate idiomkennis toeneemt.
Tabel 1. Samenvatting van taalbegrip (%) op basis van geleerde top-idiomen
| Taal | Begrip (%) per drempel van idiomwoordenschat | ||||
|---|---|---|---|---|---|
| Top 100 | Top 500 | Top 1000 | Top 3000 | Top 5000 | |
| Engels | 48.8 | 64.9 | 71.8 | 81.9 | 85.6 |
| Spaans | 49.6 | 66.3 | 73.5 | 84.1 | 87.5 |
| Portugees | 58.8 | 78.2 | 85.0 | 94.3 | 97.2 |
| Frans | 52.7 | 68.1 | 75.2 | 86.0 | 89.6 |
| Duits | 47.8 | 63.3 | 70.1 | 80.5 | 84.0 |
| Chinees | 40.3 | 56.7 | 63.7 | 74.0 | 77.8 |
| Russisch | 38.7 | 56.5 | 65.0 | 79.1 | 85.0 |
| Turks | 42.9 | 68.6 | 79.1 | 92.9 | 97.1 |
| Italiaans | 47.6 | 64.3 | 71.2 | 81.5 | 84.7 |
| Japans | 56.5 | 69.7 | 76.3 | 86.0 | 89.5 |
| Koreaans | 31.9 | 53.0 | 63.2 | 78.0 | 83.1 |
| Pools | 43.1 | 62.8 | 71.1 | 84.1 | 88.4 |
| Nederlands | 57.3 | 74.7 | 80.7 | 88.6 | 91.0 |
| Oekraïens | 36.9 | 54.4 | 63.2 | 77.4 | 83.0 |
| Zweeds | 52.9 | 71.4 | 78.1 | 86.5 | 88.9 |
| Noors | 52.8 | 70.7 | 77.4 | 86.2 | 88.6 |
| Litouws | 38.2 | 60.5 | 70.3 | 83.5 | 86.6 |
Hoewel de exacte percentages per taal verschillen, is het algemene patroon consistent: een relatief kleine set hoogfrequente idiomen is goed voor een groot deel van begrip in de praktijk. Om deze resultaten praktisch te maken, bieden de volgende secties taalspecifieke lijsten met de meest frequente woorden en idiomen, te beginnen met de top 100 voor elke taal die in deze studie is geanalyseerd.
Top-idiomlijsten om te leren per taal
→ Engels → Spaans → Portugees → Frans → Duits → Chinees → Russisch → Turks → Italiaans → Japans → Koreaans → Pools → Nederlands → Oekraïens → Zweeds → Noors → Litouws
5.2. Interpretatie van de resultaten
Er komen meerdere consistente patronen naar voren:
- Sterke winst in het begin: de eerste 500 idiomen ontsluiten een groot deel van alledaagse taal en bereiken vaak 55–75% begrip.
- Functioneel begrip bij 1000 idiomen: rond 1000 idiomen kunnen leerlingen comfortabel gesprekken volgen, vereenvoudigde teksten van moedertaalsprekers lezen en media consumeren met minimale ondersteuning.
- Gevorderd begrip bij 3000 idiomen: het bereik van 3000 idiomen komt overeen met hoge functionele vloeiendheid en overschrijdt vaak 80–90% begrip.
- Afnemende opbrengst na 5000 idiomen: extra idiomen voegen vooral stilistische nuance toe in plaats van nieuwe content te ontsluiten.
5.3. Consistentie tussen talen
Ondanks verschillen in grammatica, schriftsystemen en culturele structuur blijft de vorm van de begripscurve opvallend vergelijkbaar in alle 17 talen. Dit wijst op een universele eigenschap van taalgebruik: betekenis is geconcentreerd in een relatief kleine set hoogfrequente idiomatische patronen.
6. Waarom idiomen begrip sneller ontsluiten
Idiomen werken als eenheden van semantische compressie. Elk idioom omvat:
- Meerdere woorden
- Grammaticale structuur
- Culturele en contextuele betekenis
Het herkennen van een idioom stelt het brein in staat betekenis direct te verwerken in plaats van die woord voor woord te reconstrueren, wat de cognitieve belasting verlaagt en begrip versnelt bij zowel lezen als luisteren.
7. Implicaties voor taalleren
De bevindingen hebben directe gevolgen voor leerlingen, docenten en het ontwerp van producten voor taalleren:
- Geef vroeg prioriteit aan hoogfrequente idiomen
- Meet vooruitgang in % begrip, niet in woordenschatgrootte
- Optimaliseer leren voor echt gebruik, niet voor theoretische volledigheid
Idiomen zijn geen gevorderd materiaal — ze vormen de basis van echt begrip.
Conclusie
Je hoeft geen tienduizenden woorden te kennen om een taal te begrijpen. Je moet weten hoe de taal daadwerkelijk wordt gebruikt.
Door te focussen op de belangrijkste idiomen ontsluiten leerlingen vroeg een onevenredig groot deel van de betekenis, bereiken ze sneller begrip, krijgen ze meer zelfvertrouwen en hebben ze eerder toegang tot authentieke content. Taalbegrip groeit niet door opstapeling, maar door prioritering.
Over de auteur
Pavel Ahafonau is Head of R&D bij WRD. Zijn werk richt zich op AI-gedreven leeroptimalisatie, grootschalige taalkundige modellering en gepersonaliseerde systemen die zijn ontworpen om de efficiëntie van menselijk leren te maximaliseren.